PRMLをの勉強も兼ねて線形回帰モデルの構築をやってみたよ。 PRML本の内容とここを参考に書いてみたのでぜひ参考に。 リポジトリはこちら
最尤推定
基本的にはsin関数にガウスノイズを足した20個の訓練データからもとのsin関数が復元できるかということをやった。 1次元の多項式フィッティングの場合には最尤推定は最小二乗法でとけばいいだけなのでコードはこんな感じ。
package com.PhysicsEngine.cpistats
import breeze.linalg._
object LeastSquares {
// モデルパラメータの数 あとで正則化項を加えて計算したMAP推定と比較したいので割りとデカイ。over fittingしやすい
val M = 20
def estimate(dataList:List[Pair[Double,Double]], lam:Double) = {
// The model parameter num
val dataLength = dataList.length
// AはM+1個の微分方程式の係数行列
var A = DenseMatrix.zeros[Double](M+1, M+1)
// Tは目標値との掛け算
// 詳しくはPRMLの演習問題(1.1)を読んだ方がいいかも
// 要は微分して0とおいたときの連立方程式を解くための行列とベクトル
var T = DenseVector.zeros[Double](M+1)
for(i <- 0 to M) {
for( j <- 0 to M) {
var temp = 0.0
dataList.foreach {
dataPair => {
temp += Math.pow(dataPair._1, i+j)
}
}
A(i, j) = temp
}
}
//print(A)
for(i <- 0 to M) {
var temp = 0.0
dataList.foreach {
dataPair => {
temp += Math.pow(dataPair._1, i) * dataPair._2
}
}
T(i) = temp
}
//print(T)
val wlist = A \ T
// この連立方程式をとくとパラメータベクトルが得られる
wlist
}
}
これで解いた場合の回帰曲線がこれ
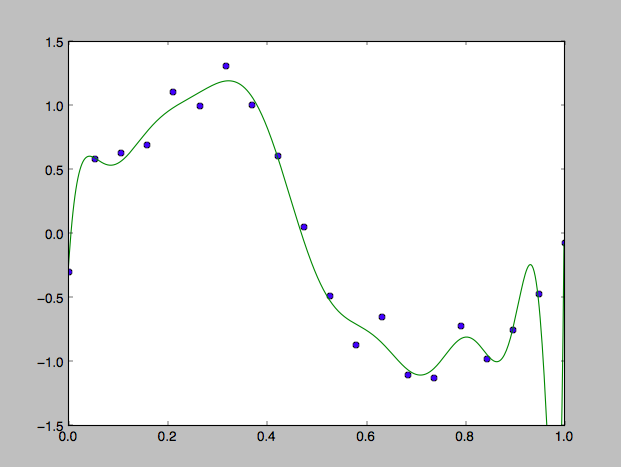
狙いどおり過学習しております。
MAP推定
過学習をふせぐために大きすぎるパラメータにペナルティを与える方法がある。これは正則化項とよばれる項を加えた上での誤差関数を最小化する方法。これはモデルパラメータの事後分布を最大化するようなものを選ぶ方法と同じ。だからMAP推定(Most a posterio)と呼ばれる。やりかたは簡単。さっきの行列Aの対角成分に正則化パラメータを加えればよい。
// これを A(i, j) = tempの前に書く
// lam = 0.00001くらいでいい
if (i == j) {
temp += lam
}
結果は以下。
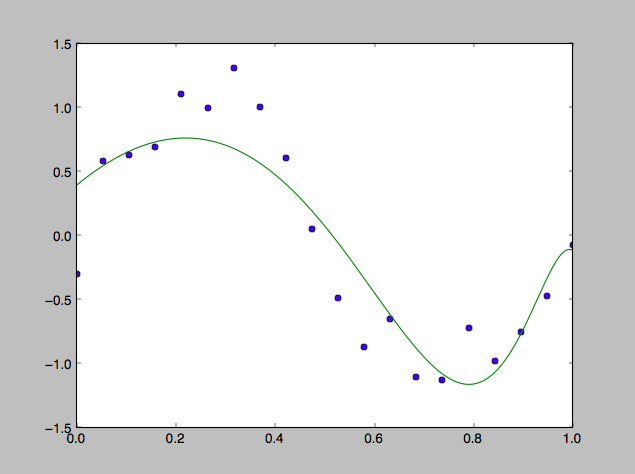
正則化項の値はかなり小さいはずなのに結構効果がある。すごい。ただずれているところはかなりずれているようにも見える。
ベイズ推定
というわけでベイズ推定。上の2つは両方ともパラメータwを点推定で決めてしまう決定論的な手法であるのに対してベイズ推定はパラメータ事後分布から予測分布を求めることまでを行う。簡単にいうと各xの値に対してパラメータwはひとつには決めずにある分布に従う確率変数として扱い、目標値に対しても幅を持たせることになる。今回は各訓練データはガウス分布にしたがうノイズがのっているという仮定にもとづいて推定を行う。
package com.PhysicsEngine.cpistats
import breeze.linalg._
object BayesEstimation {
// モデルパラメータの数
val M = 20
// BETAとALPHAは事後分布の超パラメータ
val BETA = 11.1
val ALPHA = 0.005
// 基底関数。今回は多項式関数をつかっている
def phi(x:Double) = {
var T = DenseVector.zeros[Double](M+1)
for(i <- 0 to M) {
T(i) = Math.pow(x, i)
}
T
}
// 平均値を求める
// PRML(1.70)
def mean(x:Double, dataList:List[Pair[Double, Double]], S:DenseMatrix[Double]) = {
val sums = DenseVector.zeros[Double](M+1)
for(i <- 0 to dataList.length-1) {
sums += phi(dataList(i)._1) :* dataList(i)._2
}
BETA * phi(x).t * S * sums
}
// 各平均値からの精度
// PRML(1.71) def variance(x:Double, dataList:List[Pair[Double, Double]], S:DenseMatrix[Double]) = {
phi(x).t * S * phi(x) + (1.0 / BETA)
}
}
これで推定した結果がこちら。
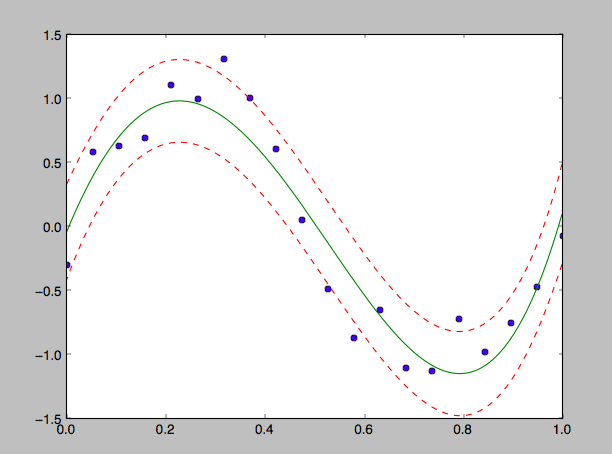
緑実線が平均値の推定結果で、赤点線がそれぞれ平均値から1σ分だけ離れた曲線を表す。大体あてはまっていることがわかる。もっとパラメータの数を多くすると無理やり、範囲内に訓練データが入るような分布が得られた。 もう少し汎用的なものを作っていこうかなと思っています。