今回はモデルのバイアスとバリアンスを前回までの正則化最小二乗法のモデルを使って計算してみたよ。線形回帰モデルのバイアスとバリアンスはトレードオフの関係にあって、表現力の高いモデルを用いるとバイアスは小さくなるがバリアンスは大きくなってしまう。逆にバリアンスの小さいモデルを用いるとデータによる差が小さくなる代わりに全ての予測値の平均が理想的な回帰関数から離れていってしまう。
20通りの異なる訓練データ集合に対して正則化パラメータを調整して、訓練させてみた。
λ=1.1の場合
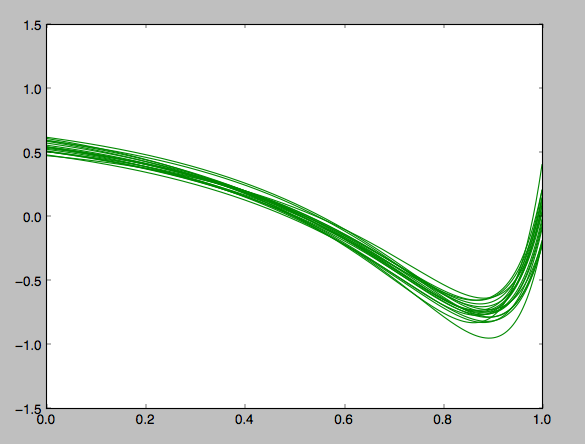
正則化パラメータが大きい場合は複雑なモデルに対するペナルティが大きくなるので、このようにバリアンスが小さく抑えられる。けれども表現力の豊かなモデルが抑えられるのでそもそも訓練データから理想的な曲線を表現できるほどのモデルになってないことがわかる。ぱっと見、さっきの正則化パラメータが小さい場合よりもずっとsin関数に見えないものができあがってしまった。
λ= 0.0000001の場合
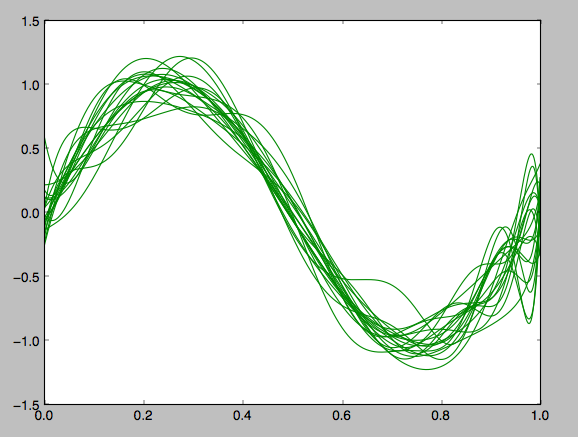
正則化パラメータが小さい場合、次元数の高いモデルに対するペナルティが低くなるので過学習を起こしやすい。この場合、それぞれの訓練データにひきずられて様々な回帰モデルが構成されてしまった。さっきよりはなんとなくsin関数に見えるけれど、あんまり、ここからどのデータが一番よいのかを決めるのも難しいし、何よりどれもかなり異なっているので全体として理想的な回帰曲線がわからない。
平均をとってみた
なんとなくsin関数に見えるということは平均をとると、正しい回帰曲線になるんではないだろうか。ということでバリアンスが高くて訓練データに引きずられてしまっている場合の平均をとってみる
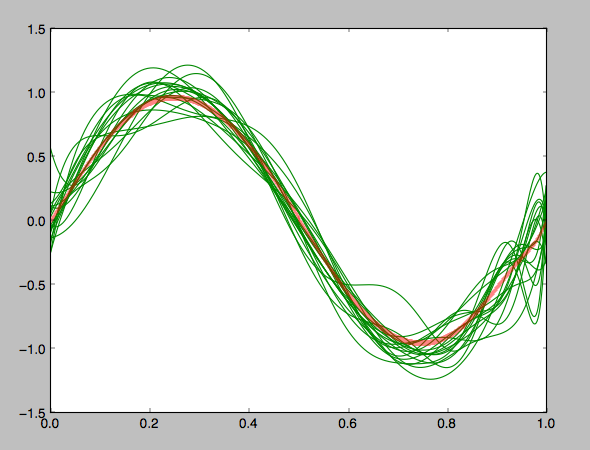
赤い太線が各推定曲線の平均。sin関数に見える!!
このことからバリアンスが大きな表現力の高いモデルの平均はいつもでもないにせよ、有益な推定結果をもたらすこともあるかもしれない。(PRMLの受け売りだけどね)